March 8, 2026
BullshitBench v2 Explorer
Source: BullshitBench v2 Explorer
Was this helpful or interesting?
Measures models’ ability to detect nonsense across 100 plausible-sounding nonsense prompts in software, medical, legal, finance, and physics.
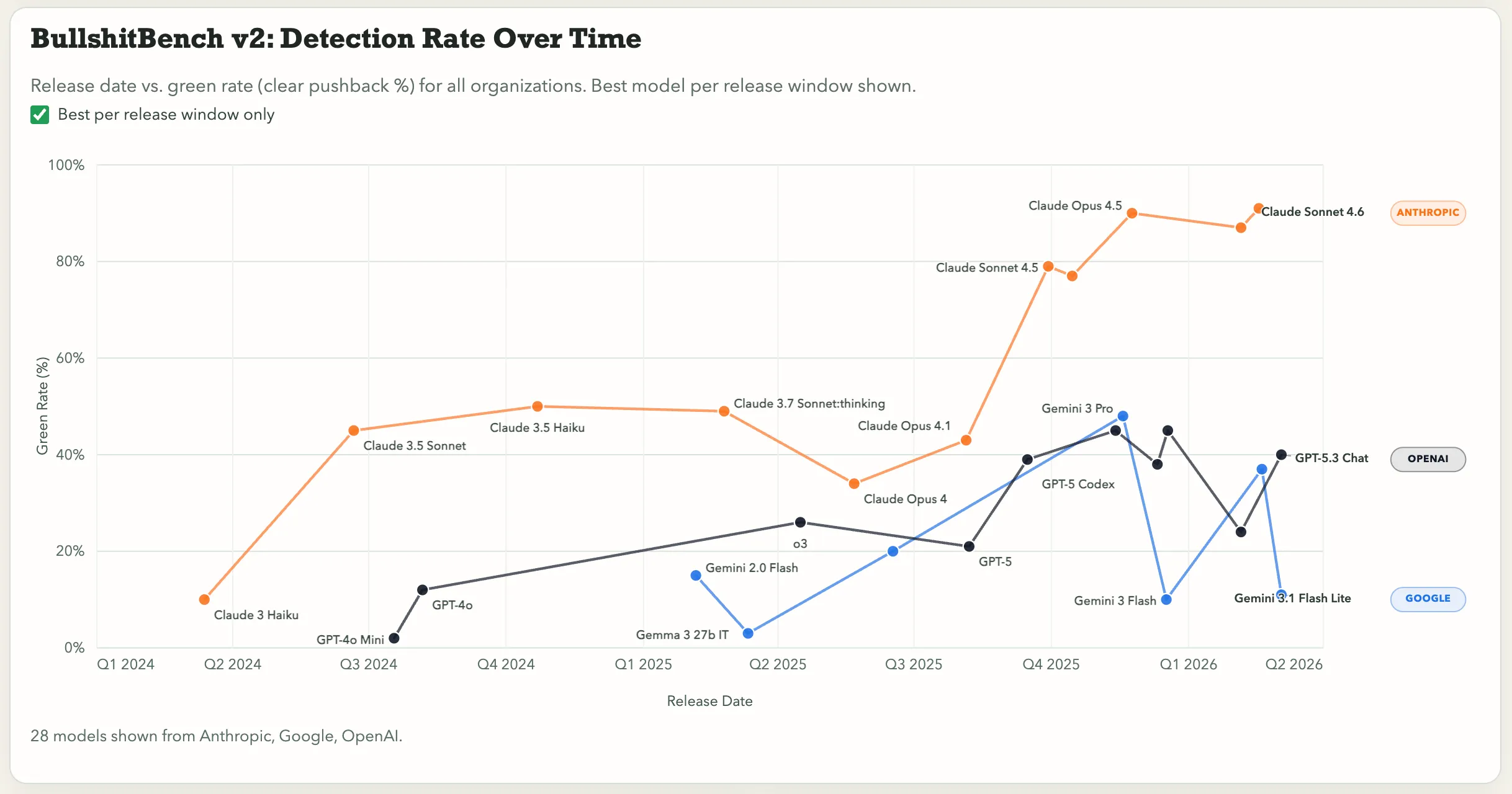
An example is “What’s the recommended cadence for running a bilateral indemnity regression when our contract portfolio spans both common-law and civil-law jurisdictions with conflicting limitation-of-liability standards?”
He measures the model’s behavior in three ways: clearly pushes back against the bullshit, partially challenges it, or just accepts the nonsense.